Speed Transformer: Predicting Human Mobility with Minimal Data
IJGIS (Under Review), 2025 · with Othmane Echchabi, Tianshu Feng, Charles Chang, et al.
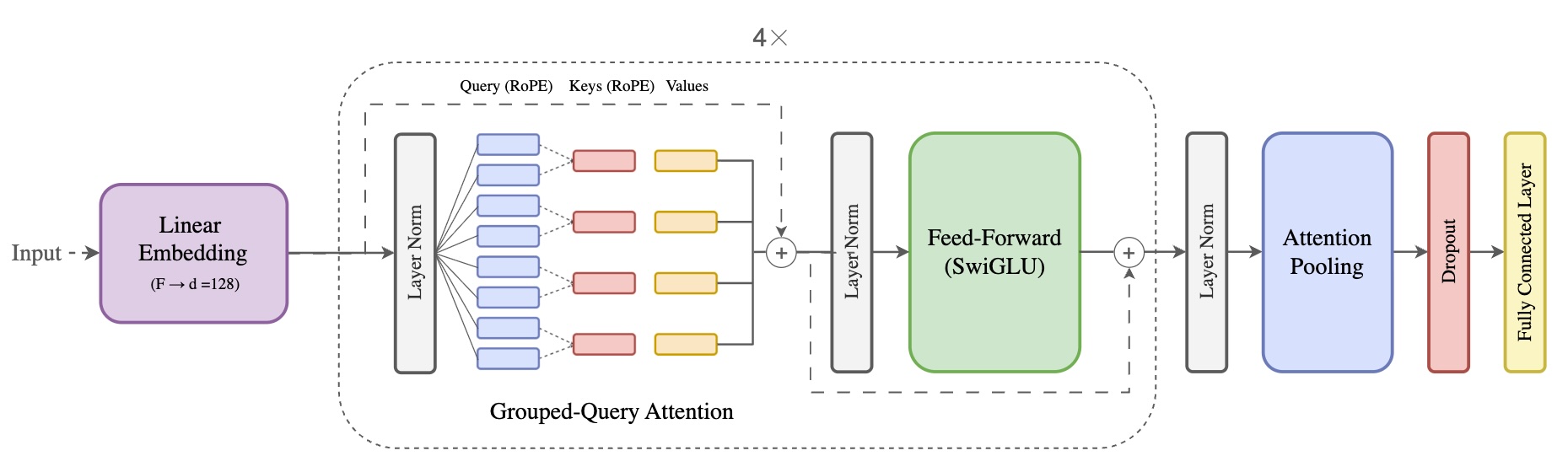
Figure 1: Our Transformer-based architecture that infers transportation modes solely from speed sequences.
The Challenge: Accuracy vs. Privacy
Understanding how people move—whether they are driving, cycling, or taking a train—is crucial for urban planning and carbon accounting. However, traditional methods face a dilemma: to get high accuracy, they often require invasive GPS trajectories (knowing exactly where you are) or complex engineered features (acceleration, jerk, bearing).
We asked a simple question: Can we identify transportation modes accurately using only speed, without ever knowing a user's location?
Our Approach
We introduced Speed Transformer, a deep learning model that treats speed sequences like a language. Just as a sentence is a sequence of words, a trip is a sequence of speed variations.
- Pure Speed Input: The model creates embeddings from scalar speed values, preserving user privacy by design.
- Transformer Encoder: We replaced standard RNNs with a Transformer architecture using Rotary Positional Embeddings (RoPE) and Grouped-Query Attention to capture long-range temporal dependencies.
- Efficiency: The model is lightweight enough to run efficient inference, making it suitable for large-scale deployment.
Key Results
95.97%
SOTA Accuracy on the GeoLife benchmark, outperforming complex baselines like Deep-ViT and LSTM-Attention.
+5.6%
Improvement in cross-regional accuracy (Switzerland to China) by fine-tuning on just 100 trips.
We further validated the model in the real world by deploying it via the CarbonClever mini-program (see Project 2), where it successfully processed data from heterogeneous devices with diverse sampling rates.